说明
说明
- 原文:https://dev.mysql.com/doc/refman/8.0/en/innodb-locks-set.html
- 下文黑色字体原文,黄色字体是翻译,红色是自己加的标注,记录自己对原文的理解。
- 测试表结构:
|
|
表里的初始数据为:
| 1 | 1 |
|---|---|
| 2 | 5 |
| 3 | 10 |
| 4 | 15 |
翻译&笔记
-
『A locking read, an UPDATE, or a DELETE generally set record locks on every index record that is scanned in the processing of an SQL statement. It does not matter whether there are WHERE conditions in the statement that would exclude the row. InnoDB does not remember the exact WHERE condition, but only knows which index ranges were scanned. The locks are normally next-key locks that also block inserts into the “gap” immediately before the record. However, gap locking can be disabled explicitly, which causes next-key locking not to be used. For more information, see Section 15.7.1, “InnoDB Locking”. The transaction isolation level can also affect which locks are set; see Section 15.7.2.1, “Transaction Isolation Levels”.』
- 一次加锁的读、更新或删除通常在 SQL 语句处理过程中扫描的每个索引记录上设置记录锁。 语句中是否使用 WHERE 条件排除了某些行并不关键。InnoDB 不会记住准确的 WHERE 条件,而是只关心索引的扫描范围。锁通常是临键锁,用来组织在记录之前的『间隙』插入记录。但是,间隙锁可以被禁用,此时不会使用临键锁。更多信息,见第15.7.1,『InnoDB Locking』。事务隔离级别也会影响锁的设置,详情见15.7.2.1,『Transaction Isolation Levels』。
- 锁是设置在索引记录上的。
-
『If a secondary index is used in a search and the index record locks to be set are exclusive, InnoDB also retrieves the corresponding clustered index records and sets locks on them.』
- 如果在搜索中使用了二级索引,并且要设置的索引记录锁是排他的,InnoDB也会检索相应的聚集索引记录并对其设置锁。
- 怎么理解?
- 『在搜索中使用二级索引』,InnoDB 在执行时是通过扫描二级索引来查找记录的,举个例子:
- 事务一,执行 begin; select * from t where version = 1 for update;
- 事务二,执行 select id from t where id = 1 for update; 会被阻塞;此时查询data_locks 表,会发现事务一在聚簇索引上设置了记录锁:

『If you have no indexes suitable for your statement and MySQL must scan the entire table to process the statement, every row of the table becomes locked, which in turn blocks all inserts by other users to the table. It is important to create good indexes so that your queries do not scan more rows than necessary.』
- 如果没有适合语句的索引,MySQL必须扫描整个表来处理语句,此时表的每一行都被锁定,从而阻止其他用户对表的所有插入。 创建良好的索引非常重要,这样查询就不会扫描不必要的行。”
『InnoDB sets specific types of locks as follows.』
- InnoDB设置锁的具体类型如下。
- 『SELECT … FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.』
- 『When UPDATE modifies a clustered index record, implicit locks are taken on affected secondary index records. The UPDATE operation also takes shared locks on affected secondary index records when performing duplicate check scans prior to inserting new secondary index records, and when inserting new secondary index records.』
- 当 Update 修改聚簇索引记录时,会隐式的对受影响的次级索引加锁。在插入新的次级索引记录之前执行重复检查扫描时,以及在插入新的次级索引记录时,UPDATE 操作还对受影响的次级索引记录加共享锁。
- 怎么理解 『隐式加锁』?
- 事务一,执行 begin; update t set version = -1 where id = 1; 然后查 data_locks 表,会发现没有对 uk_version 加锁;
- 事务二,执行 update t set version = -2 where version = 1; 会被阻塞,此时再次查看 data_locks 表,会发现事务一获取了 uk_version 的记录锁:
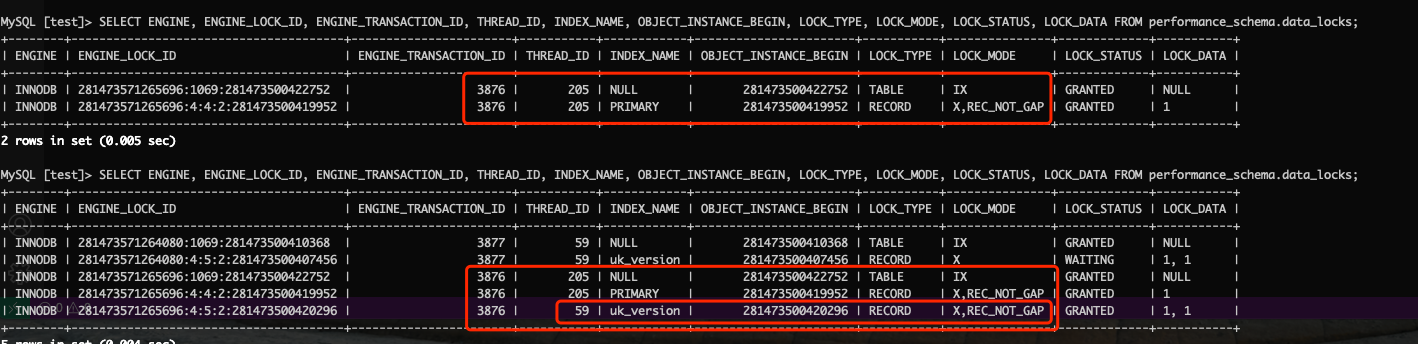
- 这说明,事务一确实会对次级索引加锁,只是不知道什么原因,没有锁
冲突是,在 data_locks 表中查不到锁记录;
- 怎么理解『进行重复性检查扫描时,会对受影响的次级索引加共享锁』?
- 执行 begin; insert into t (version) value (1); 然后查 data_locks 表,会发现事务持有了 uk_version 上的 S 锁;

- 由于表中已经有一条 version=1 的记录,当在插入 version=1 的记录时,会加一个 S 锁以进行重复检查;